As we know that PySpark is a Python API for Apache Spark where as Apache Spark is an Analytical Processing Engine for large scale powerful distributed data processing and machine learning applications.
If you are working as a PySpark developer, data scientist or data analytics and many times we need to load data from a nested data directory. These nested data directories typically created when there is an ETL job which keep on putting data from different dates in different folder. You would like to read these CSV files into spark Dataframe for further analysis. In this is article, I am going to talk about data loading from nested folders.

Note : I’m using Jupyter Notebook for this process and assuming that you guys have already setup PySpark on it.Step 1: Import all the necessary libraries in our code as given below —
- SparkContext is the entry gate of Apache Spark functionality and the most important step of any Spark driver application is to generate SparkContext which represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
- SparkSession is an entry point to underlying PySpark functionality in order to programmatically create PySpark RDD, DataFrame.
- SQLContext can be used create DataFrame , register DataFrame as tables, execute SQL over tables, cache tables, and read parquet files whereas SparkContext is backing this SQLContext. The SparkSession around which this SQLContext wraps.
- SparkConf offers configurations to run a Spark application on the local/cluster by supporting few configurations and parameters
#import all the libraries of pyspark.sql
from pyspark.sql import*#import SparkContext and SparkConf
from pyspark import SparkContext, SparkConfStep 2: Configure spark application, start spark cluster and initialize SQLContext for dataframes
#setup configuration property
#set the master URL
#set an application name
conf = SparkConf().setMaster("local").setAppName("sparkproject")#start spark cluster
#if already started then get it else start it
sc = SparkContext.getOrCreate(conf=conf)#initialize SQLContext from spark cluster
sqlContext = SQLContext(sc)Method 1: Declare variables for the file path list and you can use * wildcard for each level of nesting as shown below:
#variable to hold the main directory path
dirPath='/content/PySparkProject/Datafiles'#variable to store file path list from main directory
Filelists=sc.wholeTextFiles("/content/PySparkProject/Datafiles/*/*.csv").map(lambda x: x[0]).collect()
In my case, the structure is even more nested & complex as given below-
Read data into dataframe by using for loop
#for loop to read each file into dataframe from Filelists
for filepath in Filelists:
print(filepath)
#read data into dataframe by using filepath
df=sqlContext.read.csv(filepath, header=True)
#show data from dataframe
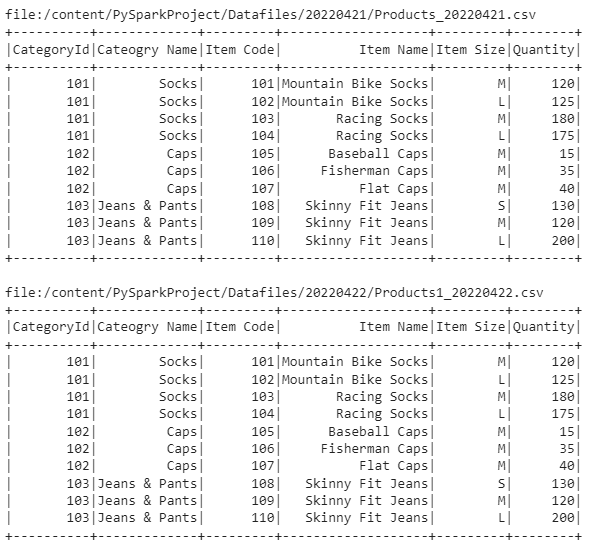
df.show()Above, read csv file into pyspark dataframe where you are using sqlContext to read csv full file path and also set header property true to read the actual header columns from the file.
Sample Output -
Method 2: Spark 3.0 provides an option recursiveFileLookup to load files from recursive subfolders. This recursively loads the files from src/main/resources/nested and it’s subfolders.
#set sparksession
sparkSession=SparkSession(sc)#variable to hold the main directory path
dirPath='/content/PySparkProject/Datafiles'#read files from nested directories
df= sparkSession.read.option("recursiveFileLookup","true").option("header","true").csv(dirPath)#show data from data frame
df.show()
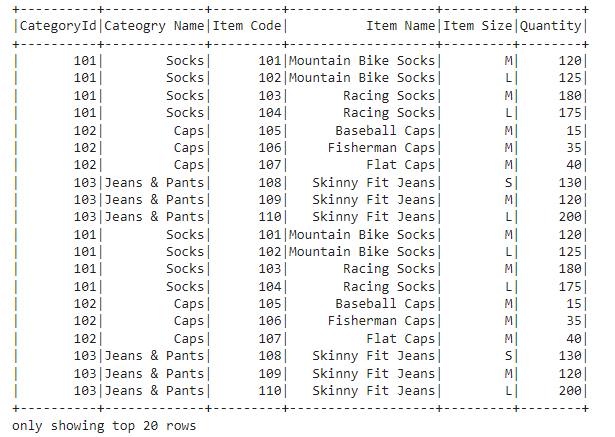
User can enable recursiveFileLookup option in the read time which will make spark to read the files recursively. This improvement makes loading data from nested folder much easier now. The same option is available for all the file based connectors like parquet, avro etc.
Now, you can see this is very easy task to read all files from the nested folders or sub-directories in PySpark.




No comments:
Post a Comment