W
# pandas library for data manipulation in python
import pandas as pd# create a dataframe with number values
df = pd.DataFrame({'Num':[5,10,15,17,22,25,28,32,36,40,50,]})#display values from dataframe
df

#create square() function to return single value
#passing variable is x
#return single valuedef square(x):
return x*x#Add new column and update value in it
df['Square of Num'] = [square(i) for i in df['Num']]#display values from dataframe
df


Problem — The actual function is returning two items, and I want to put these two items in two different new columns.
How to update multiple columns in Dataframe? If you want to update multiple columns in dataframe then you should make sure that these columns must be present in your dataframe. In case, updated columns are not in your dataframe, you have to create them as given below -
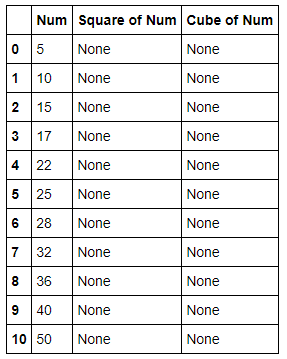
#create new columns before updates
df['Square of Num'] = df['Cube of Num'] = None#display values from dataframe
df

With the help of Pseudo code technique, we can update multiple columns at once. Pseudo code is a term which is often used in programming and algorithm based fields. It is a methodology that allows the programmer to represent the implementation of an algorithm.
Advantages of Pseudocode
- Improves the readability of any approach. It’s one of the best approaches to start implementation of an algorithm.
- Acts as a bridge between the program and the algorithm or flowchart. Also works as a rough documentation, so the program of one developer can be understood easily when a pseudo code is written out. In industries, the approach of documentation is essential. And that’s where a pseudo-code proves vital.
- The main goal of a pseudo code is to explain what exactly each line of a program should do, hence making the code construction phase easier for the programmer.
Now, we have to create a function to return multiple values as given below -
#create squareAndCube function to return single value
#passing variable is x
#return multiple value as square, cubes
def squareAndCube(x):
square = x*x
cube= x*x*x
return square, cube#below is a pseudo-code
df.loc[:,['Square of Num', 'Cube of Num']] = [squareAndCube(i) for i in df['Num']]

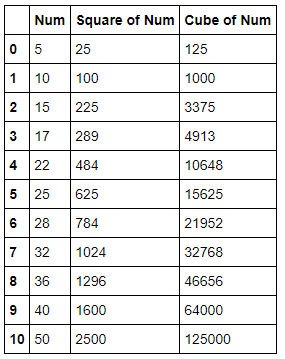
Note: df.loc takes two parameters, a list of rows you want to work on — in this case — which means all of them, and a list of columns - [‘Square of Num’, ‘Cube of Num’].
#display values from dataframe
dfWe can call the function directly as given below —
#call function directly
df['Square of Num'], df['Cube of Num'] = squareAndCube(df['Num'])#display values from dataframe
df

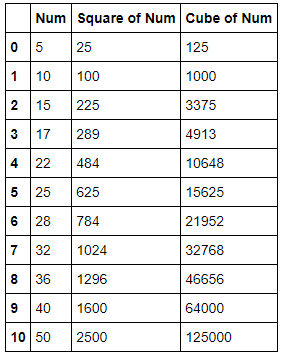
Now, this example shows you, how to update multiple columns inside your dataframe. Keep in mind that if you’re munging data, you should most probably be using pandas because it has far more elegant tools than the pure Python workarounds.
To learn more, please follow us -
http://www.sql-datatools.com
To
Learn more, please visit our YouTube channel at —
http://www.youtube.com/c/Sql-datatools
To
Learn more, please visit our Instagram account at -
https://www.instagram.com/asp.mukesh/
To
Learn more, please visit our twitter account at -
https://twitter.com/macxima